索引
- 基于本体建模的跨系统企业资源集成管理平台
- 知识图谱的构建及其在个体关系分析中的应用
- 数据中台
- 基于图像处理的肺纤维化病灶检测系统
- 多模态医疗知识图谱构建及应用
- 语义驱动的数据湖架构研究与应用
- 基于上下文的视频多语义标注研究及实现
- 基于容器的CI/CD系统Cyclone
- 基于本体的Web3D室内设计三维场景快速构建系统
- 服务组合编程模型
- 服务容器管理
基于本体建模的跨系统企业资源集成管理平台
以往信息系统中的资源只通过XML直接反映数据库中的关系型结构,而本系统通过对资源的语义封装和使用本体来管理资源,实现业务人员对数据组织形式的灵活选择,根据不同的业务需求和变更来订制不同的资源形式,进行调用,而无需修改数据库中的原有结构。
知识图谱的构建及其在个体关系分析中的应用
数据中台
基于图像处理的肺纤维化病灶检测系统

多模态医疗知识图谱构建及应用
项目背景
电子病历的推广方便了医生在病例分析前对病历数据的整理。然而在复杂病例的电子化记录中,大量诊疗活动信息不仅存在于文本中,同时也蕴含在图像等其他模态数据中,提取这些信息并形成病历总结需要花费很多时间。本文基于电子病历构建多模态医疗知识图谱,对电子病历中的多模态数据进行组织和关联,为病历自动化摘要提供支持。但是多模态医疗知识图谱的应用过程中存在以下问题:第一,多模态数据表示困难。电 子病历中存在着模态互异的数据,缺乏统一的框架来组织不同层次的多模态数据。第二,跨模态知识难以融合。同一实体在不同实例中有不同的描述形式,信息分散,难以对实例进行融合得到标准化的知识。第三,跨模态推理困难。不同模态中存在互补的信息,在对知识图谱进行应用时,难以综合不同模态信息进行互补推理。
研究内容
- 本文提出了多模态知识图谱构建及应用框架。框架主要分为三层:建模层负责设计层次化多模态知识图谱数据模型,定义多模态数据统一表示方式;构建层负责解析领域业务数据构建多模态知识图谱;应用层利用多模态知识图谱进行推理应用。
- 本文设计了支持多模态数据处理的层次化知识图谱模型。本文分析了电子病历数据特点,设计了包含概念类层、概念层和实例层的多模态医疗知识图谱数据模型。概念类层定义了知识图谱中知识表示方式;概念层描述抽象化的医疗概念实体及概念实体之间的关系;实例层描述具体实例实体及实例实体之间的关系。
- 本文提出了上下结合的多模态知识图谱构建方法。本文在概念类层定义的概念类和关联指导下,针对自由文本、医疗图像和检验数值分别使用命名实体识别、目标检测及参考区间离散化对实例数据进行知识抽取;通过跨模态实体对齐和三元组质量评估实现了多模态知识的融合,从实例中总结出概念关联,最终构建得到多模态医疗知识图谱。
- 本文提出了将多模态医疗知识图谱推理应用于电子病历自动摘要的方法。本文以电子病历自动摘要作为案例,基于实体排序进行电子病历关键信息提取,基于多模态信息互补进行医疗图像特征区域检测,研究了多模态医疗知识图谱的互补推理应用。
本文设计并实现了多模态医疗知识图谱构建及应用原型系统。本文在电子病历自动化摘要、病灶图像对比等多个应用上验证了多模态医疗知识图谱的推理应用能力,并通过和相关方法对比,阐述了本文所述方法的有效性和实用性。
语义驱动的数据湖架构研究与应用
项目背景
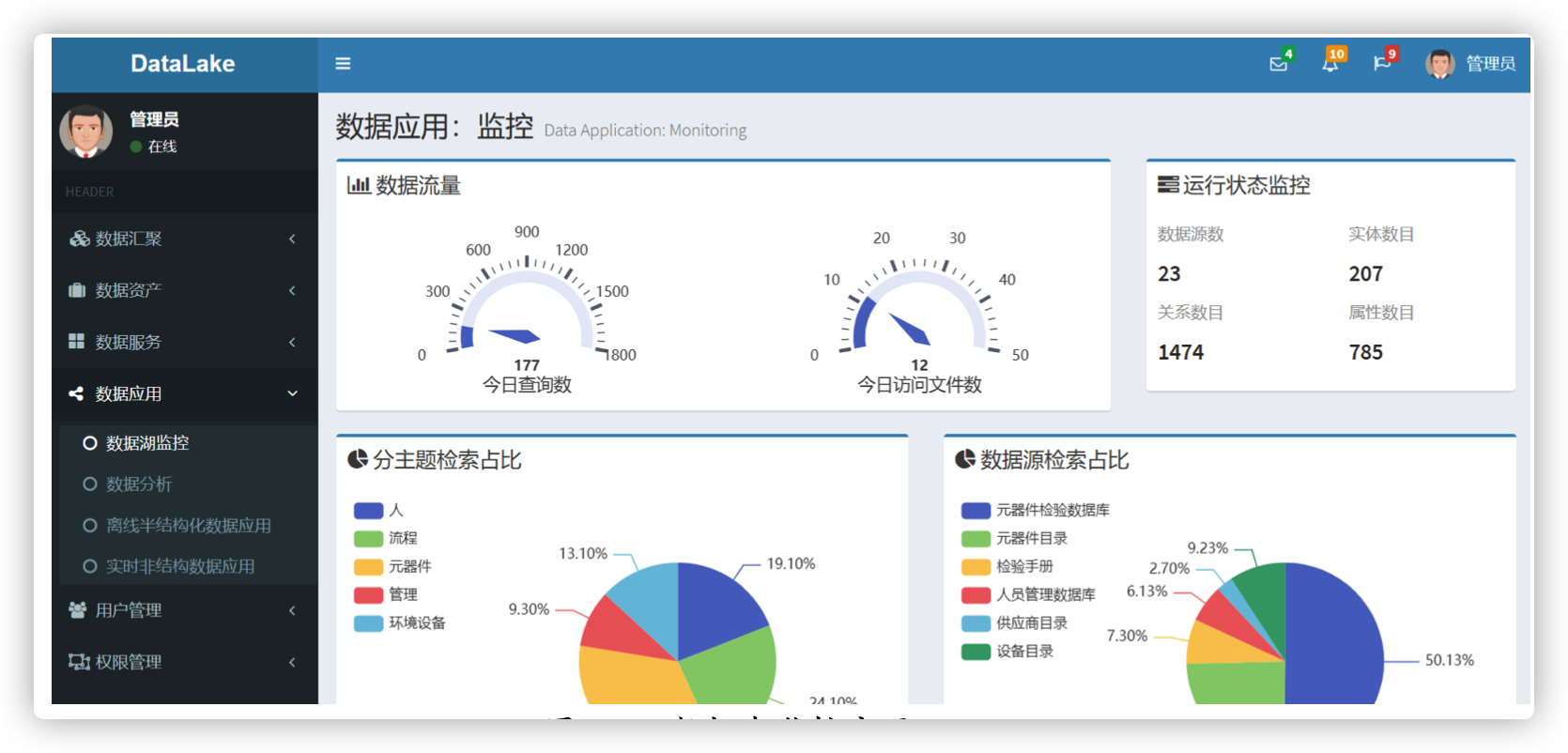
随着信息技术的发展,企业产生的业务数据量越来越大,结构也更加多样化。面向海量多源异构数据进行高效且可靠的数据分析成为了一个难题。数据湖是一种新型数据架构,能够接入结构化和非结构化的数据源,形成一个容纳所有形式数据的数据存储集。 数据湖中的数据处理方式可以看作是“读时模式”,数据会一直处于原始状态,只有在需要用来分析时才会进行转换。但是实现基于数据湖的数据分析架构时存在以下问题:第一,多源异构数据实例表示困难。来自不同数据源中的数据实例具有不同的设计规则与标准,存在结构和语义异构性,缺乏统一的数据描述与组织方式。第二,数据湖缺少持续治理机制。元数据作为治理数据湖的有效机制,初次获取后无法实现自动演化与更新,数据湖将成为数据沼泽。第三,基于数据湖的数据分析应用效率低。数据湖将数据清洗、转换和加载等数据预处理过程延迟到数据分析阶段,提升数据写入效率的同时,也提高了面向海量原始数据进行数据分析的难度。
研究内容
- 本文提出了语义驱动的数据湖构建及应用框架。框架主要分为三层:建模层负责面向多源异构数据实现数据湖语义建模,消除数据异构并构建数据湖索引;数据同步层负责数据湖数据实例的动态更新与数据湖语义元模型的演化,实现数据湖持续治理;按需调用层面向分析需求,实现了对数据湖中海量异构数据的按需调用与处理,从而支持高效且全面的数据分析应用。
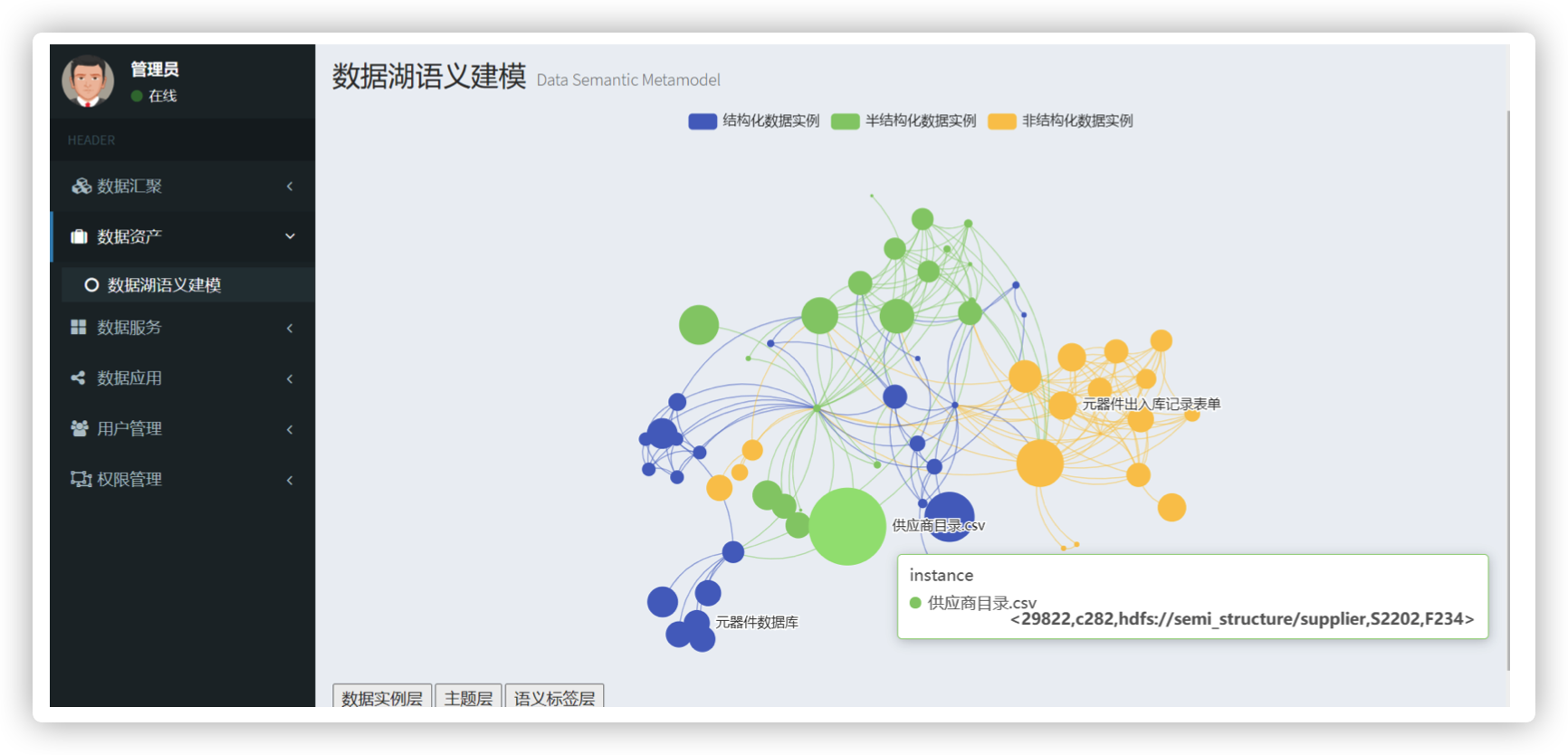
- 本文设计并实现了数据湖语义建模。面向多源异构数据,本文提出了数据湖语义元模型的架构设计与具体定义,将其分为数据实例层、主题层和语义标签层。基于模型定 义,提出面向异构数据的数据湖语义元模型构建框架与方法,实现自底向上的语义元模型构建。
- 本文提出了增量式数据同步机制。结合数据湖持续更新的特点,提出了增量式数据同步机制,实现数据实例的增量式采集与同步;基于数据实例更新项,实现主题层中结构描述集和功能描述集的更新与扩展;主题层中的结构更新项驱动语义标签层演化,设计了语义标签的自动更新算法,最终实现数据湖中数据实例的增量式更新与数据湖语义元模型的自动演化。
- 本文提出了数据湖按需调用方法。面向通过自然语言描述的数据分析需求,首先结合数据湖语义元模型中的语义标签层,将需求解析为各维度下的语义标签。其次,基于主题层及关联信息,实现自顶向下的核心属性补全、数据实例装载与分布式异构数据处理。最后,设计基于多实例加权平均的结果综合算法将数据实例进行排序后,有序返回作为数据湖按需数据调用方法的最终结果,实现按需展开数据处理与计算,支持基于数据湖实现高效且全面的数据分析应用。
- 基于本文提出的方法,以航天元器件的质量分析为业务背景,构建了一个基于数据湖的航天元器件质量分析平台的原型系统,验证了本文方法的有效性。
基于上下文的视频多语义标注研究及实现
项目背景
随着计算机处理能力和互联网技术的飞速发展,多媒体数据包括图像和视频能够承载更多的信息,因此方便用于记录和传播信息。视频拍摄工具的广泛使用使得用户可以非常方便将视频数据通过网络进行分享。这些就导致视频不但内容丰富,而且数量正在以惊人的速度增长,然而面对如此海量的数据,如何找到视频中用户感兴趣的内容已经超出了单个用户的能力范围。因此如何对这些多媒体数据进行高效的检索和有效的管理成为了一个新的挑战。
研究内容
- 将输入的视频进行分析处理得到其中包含的概念,必然需要提出其低层特征信息,这些特征包括视频的结构信息和内容信息,在结构上分为上下垂直结构和水平结构,内容上分为视频的颜色特征、纹理特征、形状特征以及多特征结合等,然后需要什么样的特征和如何提取它们都是需要解决的问题。还有一个就是根据视频内容的信息,提取出其中的特征帧,特征帧的匹配标准也是依据上述低层的特征。
- 得到视频的特征帧之后,首先要将其划分为区域,因为一个特征帧不止包含一个对象;本研究基于已有的方法并针对其不足之处提出了一个改进的区域划分方法。然后再将提取区域,输入CNN 学习框架Caffe进行识别;ImageNet数据集,构建自己数据库,训练分类模型,然后再利用训练好的模型进行分类。最后利用视频的垂直结构信息构建视频树模型进行标注整合。
- 针对标注结果的漏检和误检的问题,提出了一个基于模糊图的优化方法;视频中出现的各个概念对象一般都是有联系的,而不是孤立存在的,模糊图论可以将这种关联关系进行数学建模,利用构建好的模型结合视频树进行优化。然后再针对特征领域内的视频数据,统计概念的关联关系,构建模糊图进行实验验证,以验证本文方法的有效性。
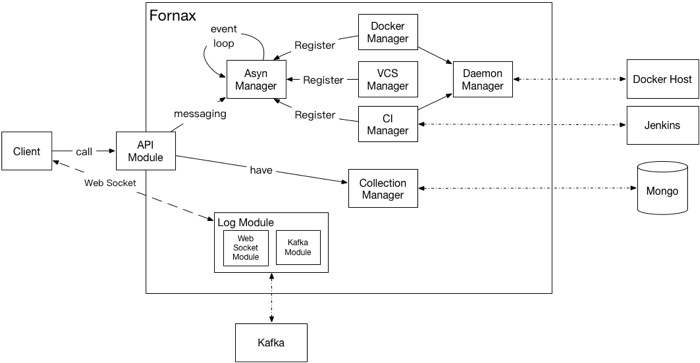
基于容器的CI/CD系统Cyclone
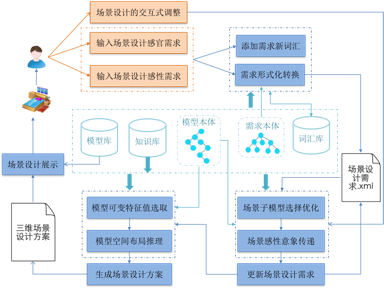
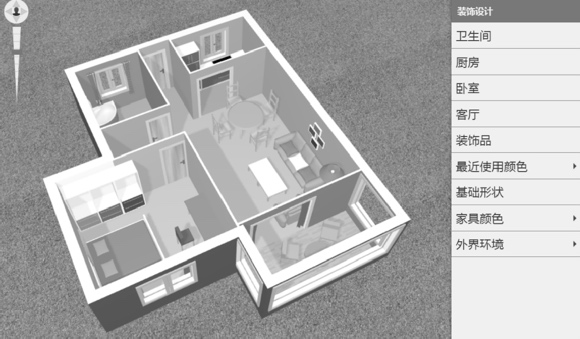
基于本体的Web3D室内设计三维场景快速构建系统

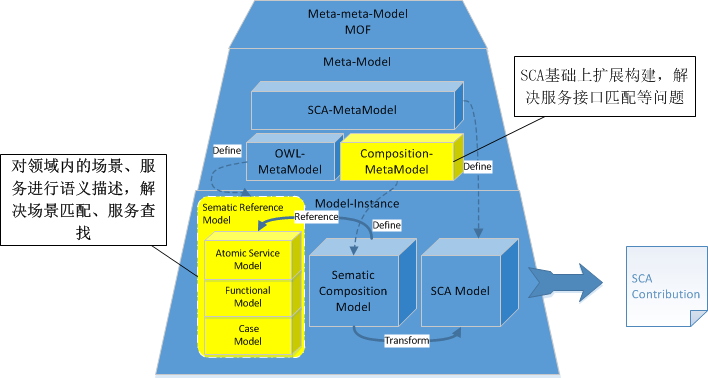
服务组合编程模型

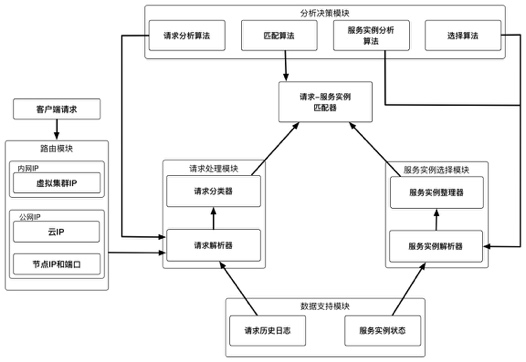
服务容器管理
- 在容器集群上的版本发布与管理系统,基于容器集群来进行持续集成与持续发布
- 容器集群系统的负载均衡算法,基于应用请求的资源需求以及容器集群的实时负载信息进行负载均衡